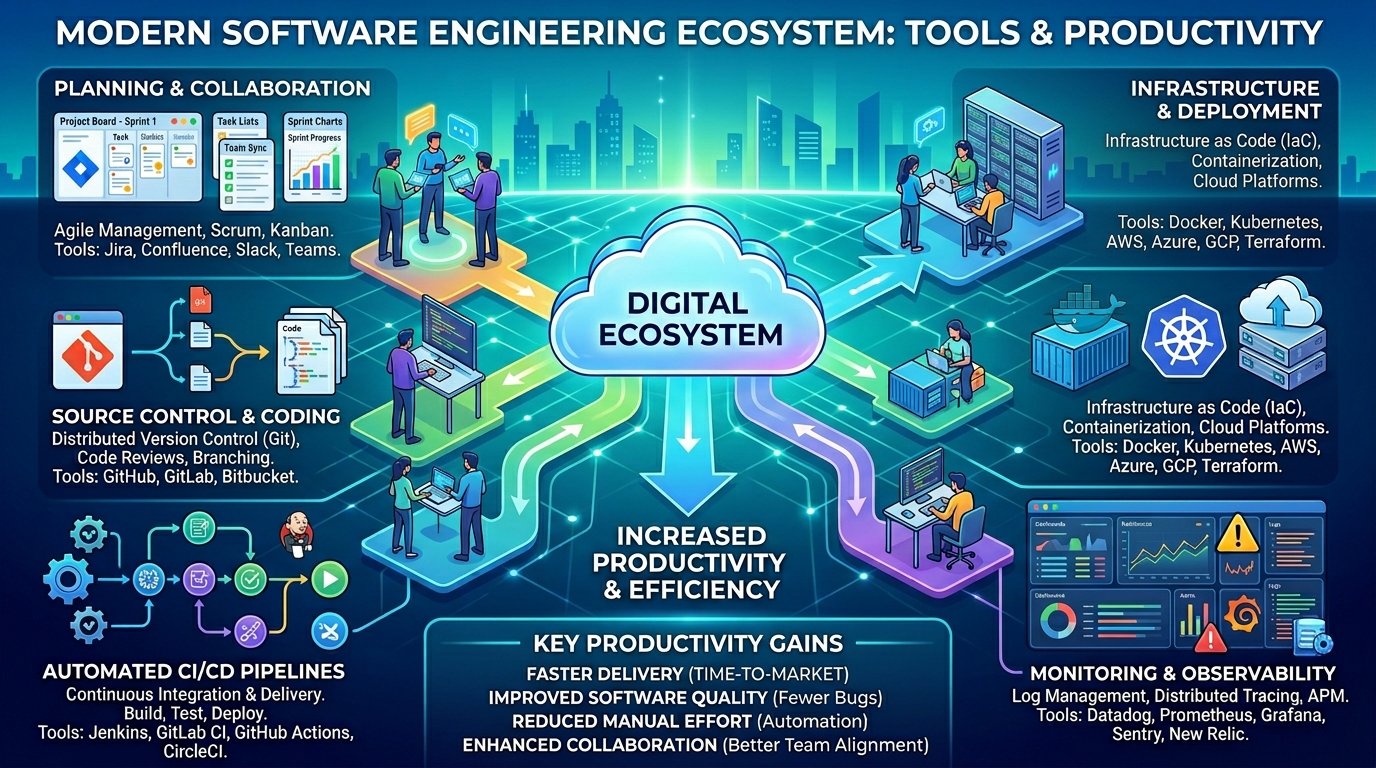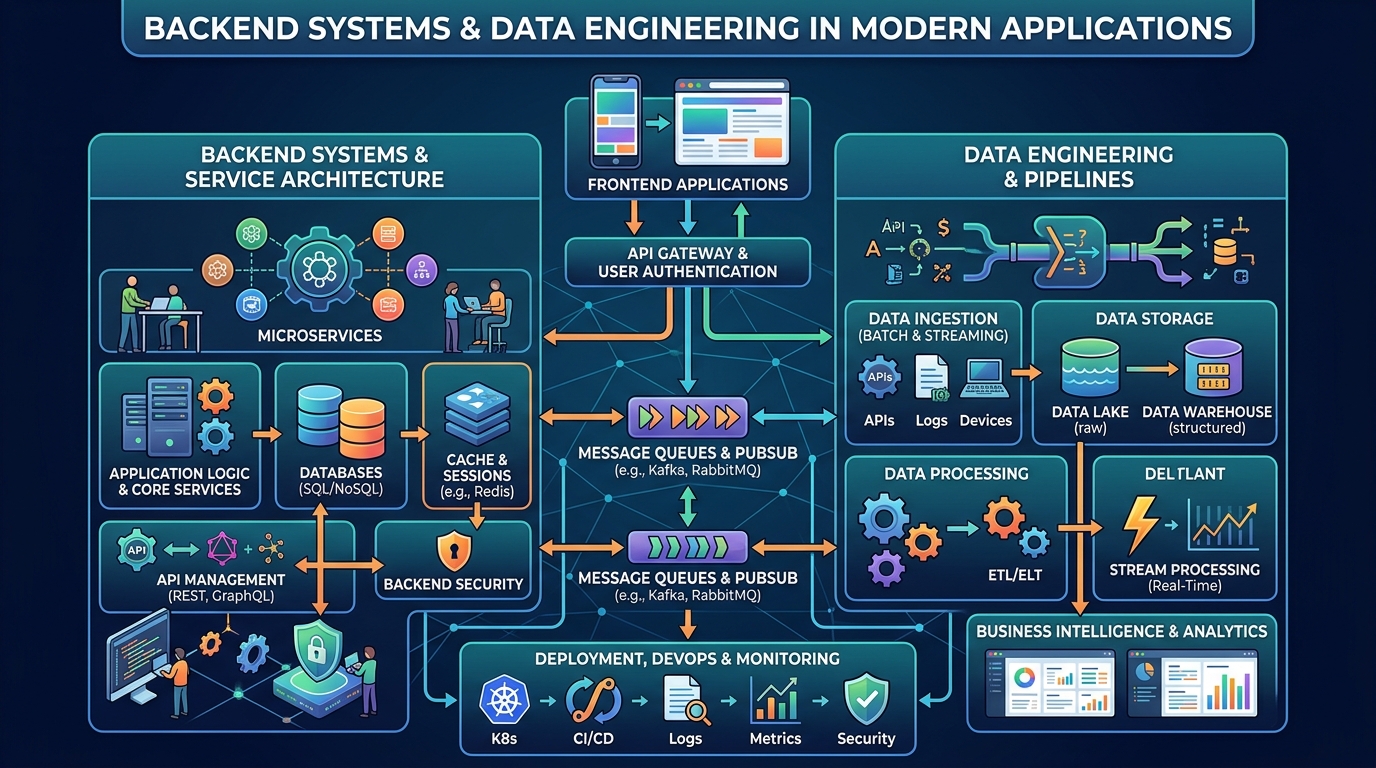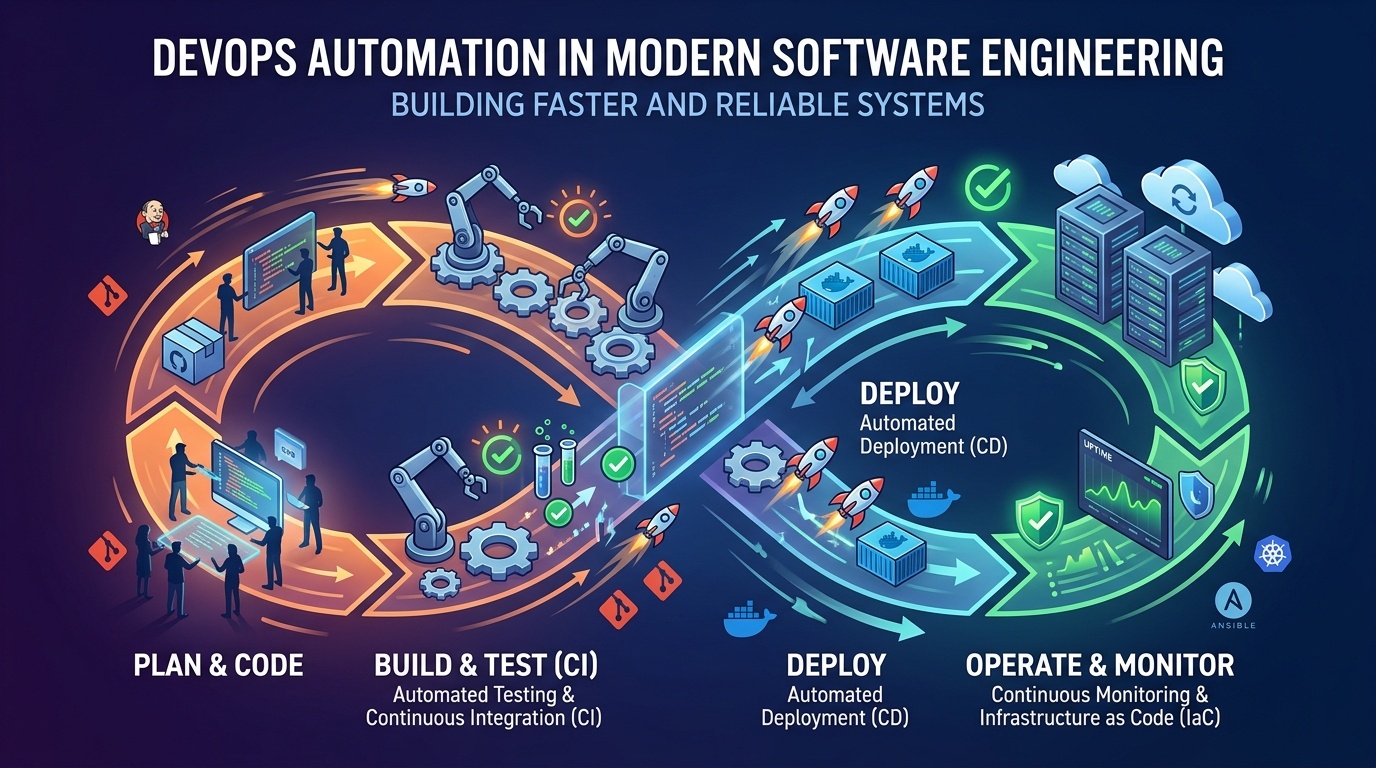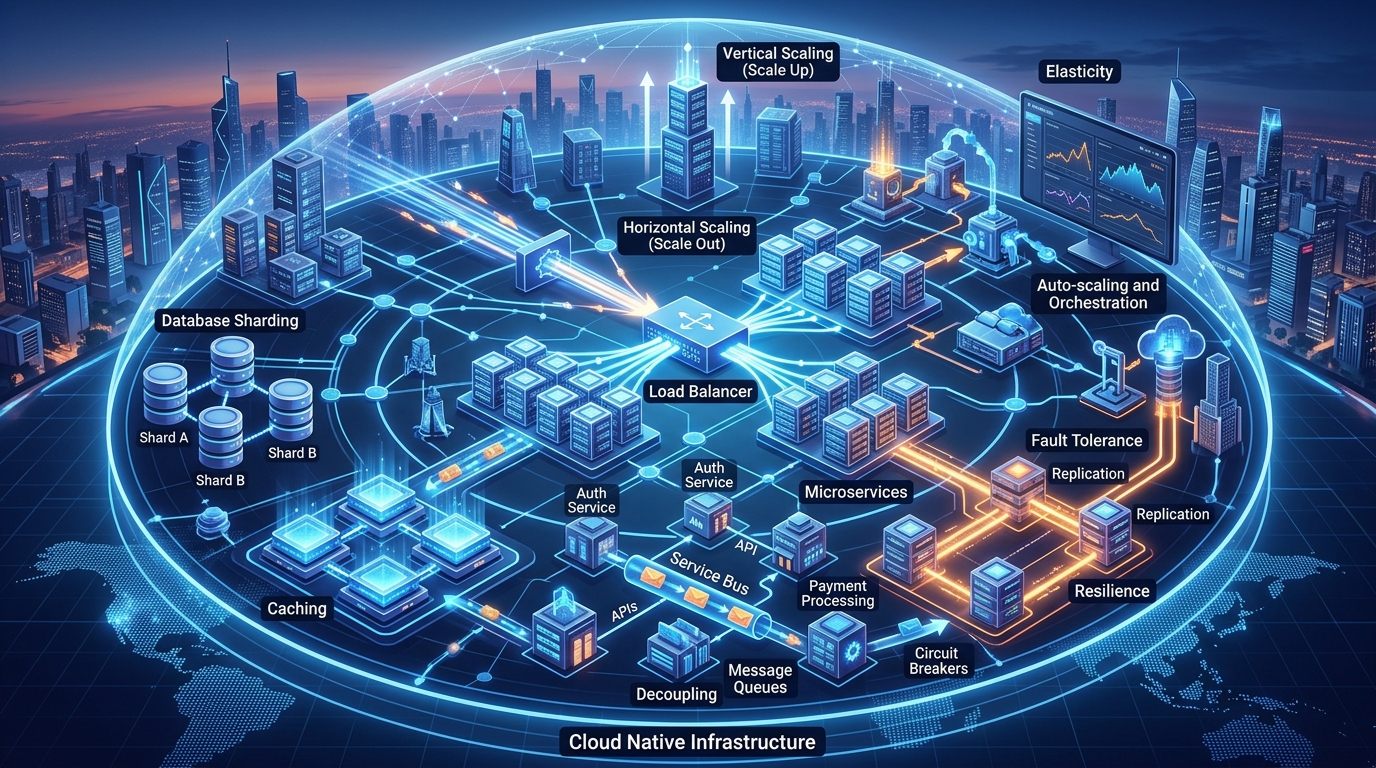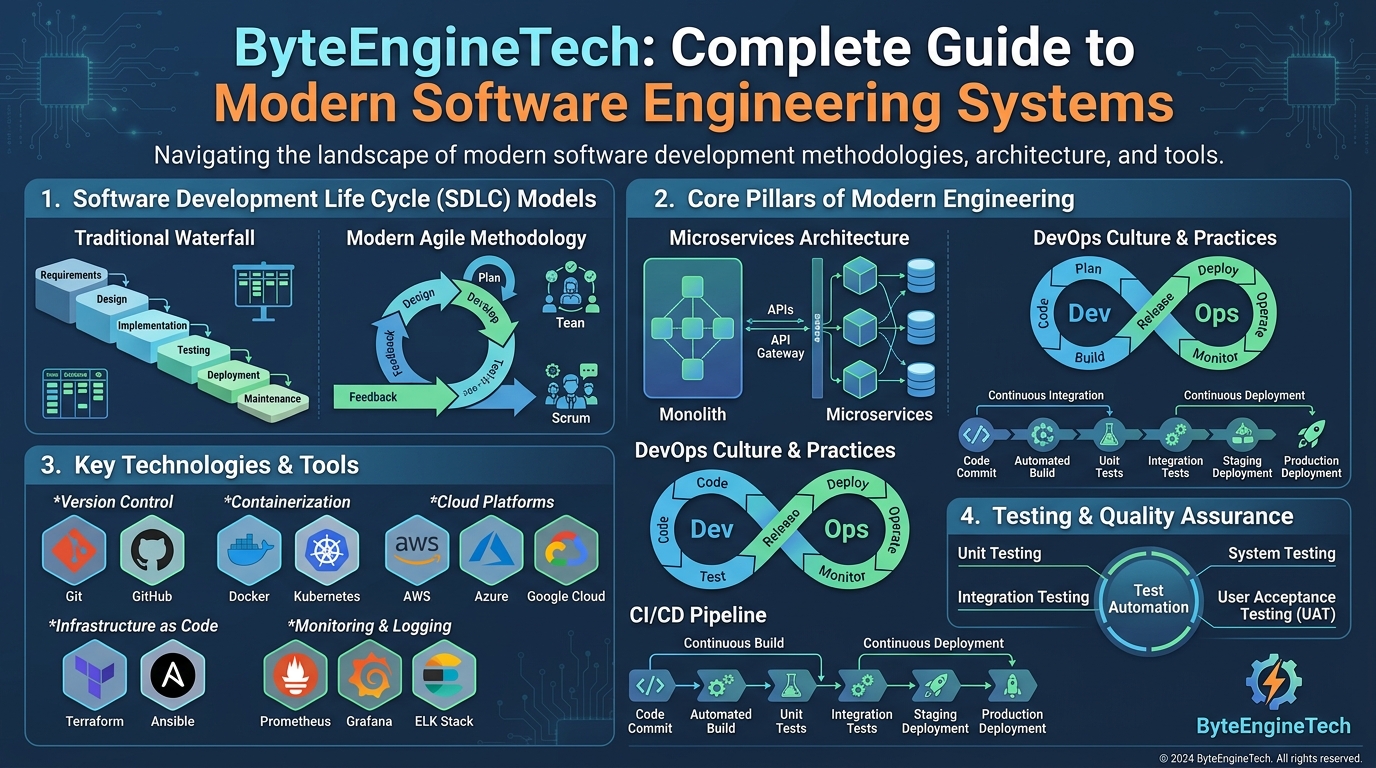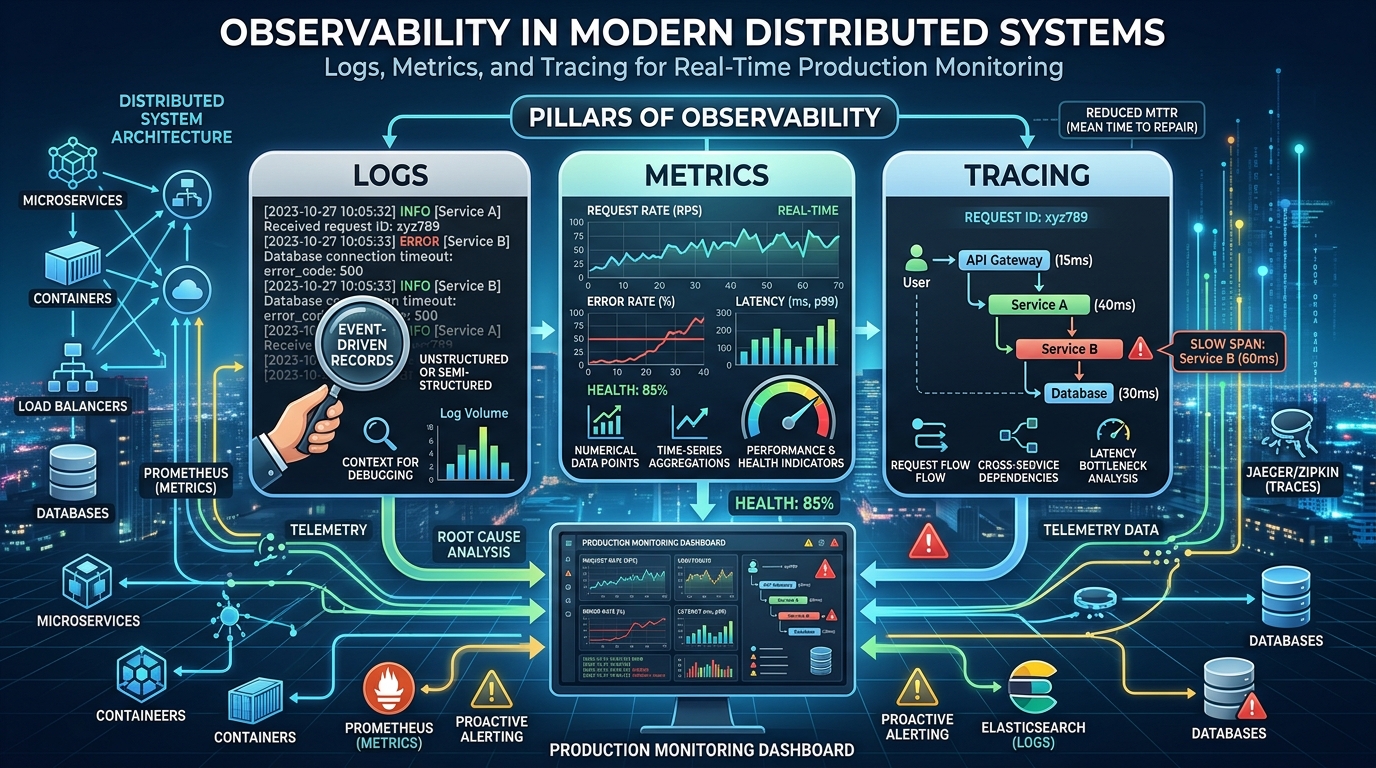
Observability is a core concept in modern software engineering that helps developers understand what is happening inside complex systems. As applications become more distributed and scalable, traditional debugging methods are no longer enough. Observability provides deep visibility into system behavior using logs, metrics, and traces, allowing engineers to detect issues quickly and maintain system reliability in production environments.
System Visibility Through Logs and Metrics
Logs are detailed records of events that occur inside an application. They capture information such as errors, user actions, and system activities. These logs are essential for debugging because they help engineers trace what happened at a specific time and identify the root cause of issues.
Metrics, on the other hand, provide numerical data about system performance. These include CPU usage, memory consumption, request latency, and error rates. By analyzing metrics over time, engineers can understand system health and detect performance degradation before it affects users.
Distributed Tracing in Microservices Systems
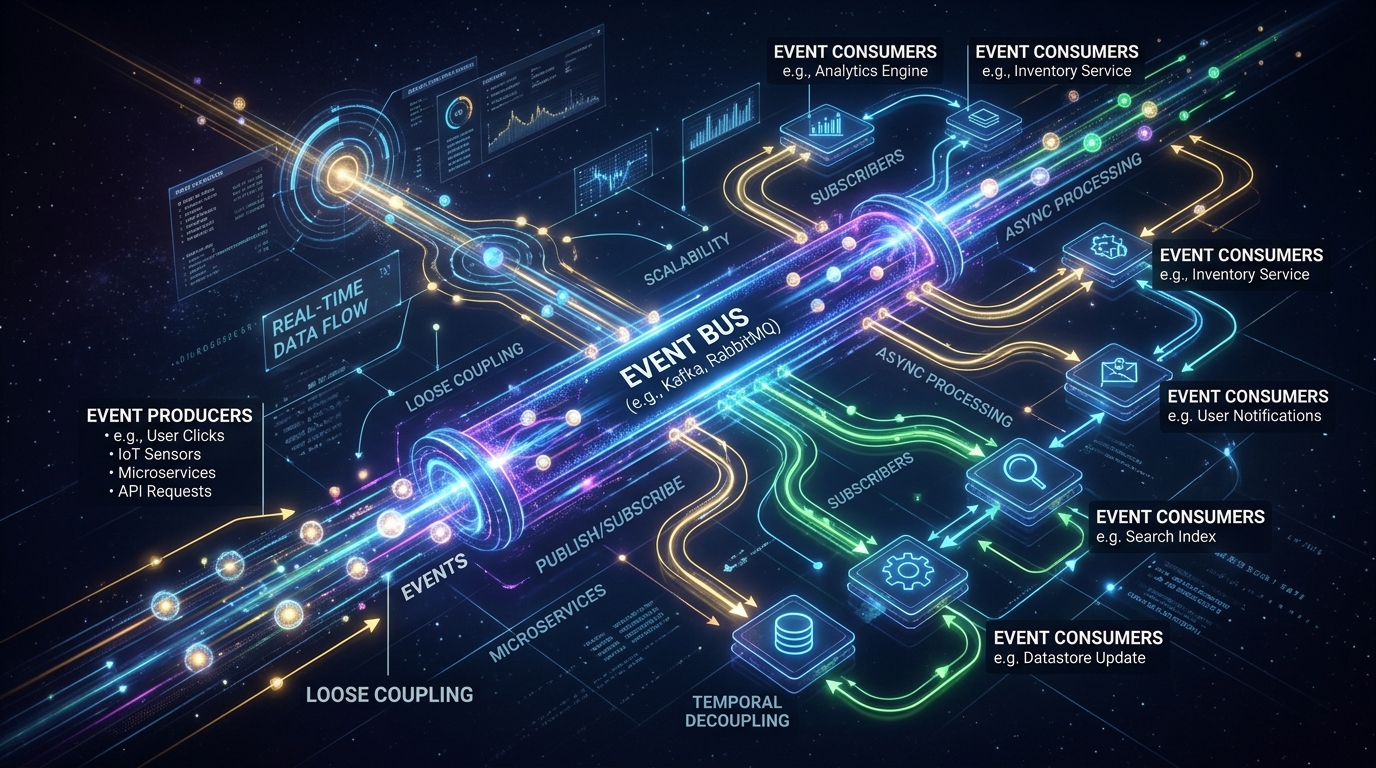
In microservices-based architectures, a single user request often passes through multiple services. Distributed tracing helps track this journey across all services. It shows how long each service takes to respond and where delays or failures occur.
Tracing tools assign a unique identifier to each request, allowing engineers to follow its path across the entire system. This is especially useful in large-scale systems where multiple services interact, making it difficult to identify performance bottlenecks without tracing.
Real-Time Monitoring and Alert Systems
Real-time monitoring
Alert systems are built on top of monitoring tools and notify engineers when predefined thresholds are crossed. For example, if error rates increase or response times become slow, alerts are triggered immediately. This proactive approach reduces downtime and improves system stability.
Improving System Reliability Through Observability
Observability improves overall system reliability by giving engineers full visibility into system behavior. Instead of guessing the cause of a problem, they can analyze logs, metrics, and traces to find exact issues. This reduces debugging time and improves response efficiency.
It also helps in performance optimization by identifying slow services, inefficient queries, and resource bottlenecks. Over time, observability data helps teams make better architectural decisions and build more stable and scalable systems.
Frequently Asked Questions
What is
It is the ability to understand system behavior using logs, metrics, and tracing data.
Why are logs important
Logs help track events and errors inside an application for debugging and analysis.
What are system metrics
Metrics are numerical values that show system performance like CPU usage and response time.
What is distributed tracing
It is a method used to track requests across multiple services in a distributed system.
Why is observability important
It helps engineers detect issues faster and improve system reliability and performance.
Conclusion
Observability is essential for managing modern software systems because it provides deep visibility into system behavior. By using logs, metrics, and tracing together, engineers can quickly detect problems, optimize performance, and ensure system stability. As systems continue to grow in complexity, observability becomes a critical requirement for maintaining reliable and scalable applications in production environments.